学院资讯
人机合作屏幕屏幕2600万个数据,所有七个基准均
作者:365bet亚洲体育日期:2025/07/08 浏览:
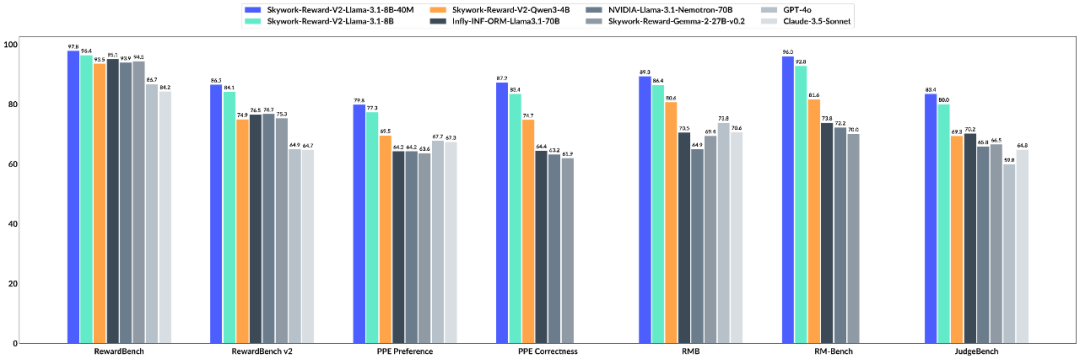 大语言模型(LLM)以这一代人的强大能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类反馈的强化学习(RLHF)用于解决此问题。奖励模型(RM)起裁判的重要作用。特别负责标记LLM产生的内容,并告诉模型什么是好是坏,这可以确保大型模型的“三个视图”是正确的。因此,奖励模型对大型模型的能力至关重要:它需要准确地判断它,需要一般涵盖许多知识领域,并且还需要具有灵活的酌处权,能够处理大量的输入,并且可以进行足够的衡量。 7月4日,国内AI技术公司发布了Kunlun Wanwei,然后是一代有益的模型Skywork-Reward-V2系列,该系列重新提出了该技术的上限。 Skywork-Reward-V2系列包括8个基于不同的基本模型和不同的尺寸,参数测量为6亿至80亿。它通过七个模型模型的评论赢得了第一名。 Skywork-Reward-V2系列模型在主要基准测试中的成就。同时,一系列模型显示了各种各样的可用性,这些可用性在许多技能方面都表现良好,包括抵抗通用对齐,客观准确性,安全性,偏见风格和最佳N扩展功能。 Skywork-Reward-V2系列模型当前是开放资源。技术报告:https://arxiv.org/abs/2507.01352HuggingFace地址:https://huggingface.co/collections/skywork/skywork/skywork-workwork-word-ward-v2-685cc86ce5d9c9c9e4be500c500c84bbe500c84github: https://github.com/skywamoi/skywork-word-v2实际上,去年9月,AI接受了Skywork-Reward系列和数据集的第一个开源。在过去的九个月中,这项工作已被广泛用于开放社区资源的研究和技能超过750,000次,在Embrace Face Platform上的总下载,并帮助许多切割模型在奖励台阶等权威审查中获得了结果。目前,Kunlun Wanwei的开放奖励模型可以引起更多关注。创建一十亿人类的偏好数据以使大型模型的产出始终符合人类偏好并不是一件简单的任务。由于Gawsain在现实世界中的复杂性和多样性,奖励模型往往只能作为完美偏好的不完美代理使用。在优化奖励模型时,不完美会导致过度优化的问题 - 模型可以照顾奖励模型的偏差并偏离人类偏好。从实际结果中的判断,当前最敬业的开放资源奖励模型仍然无法在基本审查的大多数基准上正确执行。他们通常无法有效地获得人类偏好的详细且复杂的特性,尤其是在面对多维的情况下AL和多层次反馈,它们的功能特别有限。此外,许多奖励模型容易在特定的活动中剩余的效果,但是很难进入新任务或新情况,显示出明显的“过度拟合”。尽管研究试图通过优化操作,改善模型架构的目标以及最近出现的奖励模型来提高性能,但总体影响仍然有限。左图:比较31个顶级开放奖励模型的功能;适当的图片:校正分数 - 可以看出,许多模型通过奖励台式提高了其性能,但是他们在其他基准测试上的分数是“停滞”,这可能意味着过度拟合。同时,由OpenAI的O系列模型代表的模型和DeepSeek-R1促进了“通过可验证的奖励加强”(RLVR)程序的开发,并判断产生鸡的成果是否通过特征符合预设的需求是否达到预设的需求TER匹配,系统的单元测试或更复杂的多规则匹配机制。尽管这种方法在某些情况下具有高控制和稳定性,但它们自然很难获得复杂而复杂的人类偏好,因此在优化开放式,高度主观的任务时存在明显的局限性。在这方面,Kunlun Wanwei试图在两个主要数据构建方向和基本模型中解决该问题。首先,他们建造了Skywork-synpref-40m,这是最大的混合数据集偏好,其中包含4000万对偏好样品。它的主要变化在于选择“人机合作,两个复发阶段”的管道。 AOF两阶段优选数据排序过程。如图所示,此过程分为两个主要阶段:第一阶段,小规模,由人类指导的优先型的高质量构造。在此阶段,研究人员创造了一种双轨机制,“缺乏高质量ality data → Poor model → Low quality data" that may exist in RLHF. On the one hand, they used limited manual accuracy to break the initial bottleneck, and on the other hand, they used the model's own capabilities to achieve major successes. Specifically, the artificial and large models will mark the "gold" and "silver" preference data respectively, and the reward model will be trained in silver data, and compare it to gold data to assess its shortcomings. Next, the系统将选择类似的Kagustuhan在当前的奖励模型中表现不错,并将其重新训练以重复使用此过程,第二阶段是完全较大的范围。接受了人类数据和指南的培训通过一致性机制选择数据。由于此阶段不需要制造商,因此可以将其扩展到数百万个数据偏好对。从有效性的角度来看,这个过程结合了基于人类偏好大语模型(LLM)的Manu -Manu质量保证,以实现高可扩展性。最终,最初的4000万个“减肥”样本是2600万个选定的数据,这不仅大大减轻了Manu -Manu -labeling的负担,而且在规模和质量之间达到了良好的平衡。按音量限制进行突破:参数是数十倍不同的次数,仍然可以用作由人类数据组合培训的Skywork-Reward-V2系列模型,实现了超出预期的功能。与去年9月发布的Skywork-Reward相比,工程师在Skywork-Reward-V2系列中培训了8种奖励模型,该模型的规模更大。我们将从表格中看到在Skywork-Reward-V2下方,根据基本模型审查基准(例如RewardBench V1/V2,PPE,RMB,RMB,RM Bench和JudgeBench的偏好)创造了MGA记录的最佳记录。在SOTA结果的背后,我们可以得到以下主要发现:首先,提高数据质量和财富具有很大的参数量表限制,因此可以通过在特定任务中的小型专家模型来完善奖励模型。例如,借助RewardBench V2基准评论模型的奖励,Skywork-Reward-V2显示了准确符合说明的残留功能。即使是最小的Skywork-Reward-V2-QWEN3-0.6B,也以上一代最强模型的最强差距(Skywork-Reward-Gemma-2-27b-v0.2)非常令人不安,参数刻度的全部差异为45倍。到目前为止,Pag-wark-reward-v2-qwen3-1.7b与当前的开放式SOT-INF-FORM-FORM-LALMAMA型号3.1-70B型号和某些指标是BEYOND(数学,数学)。最大的Skywork-Reward-V2-Lalama-3.1-8B和Skywork-Reward-v2-llama可以通过研究纯粹的偏好代表性,而不是强大的封闭源模型(Claude-3.7-sonnet),并且可以实现所有大型BENCH RESMPRERD MERCARDERS MERPORDERS MERPORDERS MERPORDERS。奖励基准基准结果v2。提高运营分数意味着工程技术的作用变得越来越重要,目标和质量培训数据可以支持“小到大”。此外,数据驱动的 +结构优化已足够的UPG将与简单的堆参数竞争,并且培训模型的彻底训练模型也值得考虑。其次,随着人类价值的改善结构结构结构,奖励模型开始从“弱管理得分手”转变为“强大的总体价值模型”。根据法官评估的客观基准,Skywork-Reward-V2的一般性能比某些专门用于推理和编程的封闭源模型(例如OpenAI系列)弱,或者比所有其他模型都更好。其中,Skywork-Reward-V2-llama数学性能的表现达到了相同的O3-Mini(高)水平,而Skywork-Reward-V2-llama-3.1-8b取得了更好的结果。在法官基准中,在领先的LLM-AS-A-A-Gudge模型(例如GPT-4O和识别模型(O1,O3系列))上进行功能的比较。在正确分析的基准的另一个目的,PPE的准确性,八个Skywork-Reward-V2系列模型显示了Bon(最佳N)强大的能力(最佳-N),这两个指标都超过了先前的SOTA GPT-GPT-4O模型,最高含量为20点。此外,从下面的五个困难PPE准确性工作的BON曲线中,可以看出Skywork-Reward-V2显示出持续的正量表能力,全部达到Sota。同样在其他高级技能分析(例如偏见抗性测试(RM BENCH),对真实性的教学和判断的复杂理解(RewardBench V2))中,Skywork-Reward-V2处于领先地位,表现出强大的能力和实用性。在RM Bench中,这更加困难,并且专注于模型的评论以打击风格的偏见,Skywork-Reward-V2获得了SOTA。最后,在随后的多次复发练习中,精细筛选和过滤后的首选数据可以继续并有效地改善奖励模型的整体性能,一旦重新增强了Skywork-SynpRef数据集的规模和质量优势,并突出了“较少但独特的” Paradig的魔力。为了证明这一点,工程师试图尝试使用1600万个数据子集的早期版本,结果表明(以下)仅使用1.8%(约290,000)的高质量数据来训练一个超过当前70B SOTA奖励模型的8B量表模型。 Th该图的e显示了整个数据过滤过程的奖励模型得分的变化(包括原始数据,-Filter数据,-Filter校正偏好对分为三个阶段);右图显示了Skywork-Reward-v2-llama-3.1-8b奖励模型(即Llama-3.1-8B-BTRM)的初始版本的平均得分。可以预料的是,尽管奖励模型的界限继续扩展,但它将在理解多维偏好,复杂的决策审查以及未来人类价值的一致性方面发挥更重要的作用。结论一系列来自Skywork-Reward-V2的经验结果发出了这样的观点,即随着数据集本身的构建成为一种建模行为,它不仅会改善当前奖励模型的性能,而且还可以在将来触发“由数据驱动”中的Thetechnologies的进化而进行。对于奖励模型的实践,传统的偏好数据通常取决于Manu -Annotation,这不仅昂贵且无效,而且有时会发出噪音。通过大型语言模型的注释自动组合,人们手动验证了注释的“ AI指南”标签,该标签可以结合人类的准确性和AI速度,从而实现了大规模生成的首选项数据,这为提高大型模型的功能奠定了基础。当此时发布Skywork-Reward-V2时,Kunlun Wanwei说,未来数据基于人类 + AI的方式也可以激发大型模型的潜力。除了再次开放的资源奖励模型外,Kunlun Wanwei拥有ILTHE SCALE是从2025年初到现在,该行业中最开源的SOTA大型模型的AI公司之一。它的开放资源包括:软件工程(SWE)自主代码智能人体基础模型“ SkyWork-SWE”:在S下调整行业仓库级别的最强功能开放资源32B模型的IZE;太空智能模型“矩阵游戏”:行业的第一个开源10b +太空智能大型模型; “ SkyWork-R1V”模型的多模式思维链推理:成功传递了强大的文本季节能力向视觉模式传递;视频生成系列的模型:Skyreels-V1,以及今年4月发布的迭代版本 - 使用Skyreels-V2大纲的扩散,全球电影一代的首个模型; MA数学代码“ SkyWork-OR1”的MA模型:它在相同的参数量表下实现了导致行业的性能,进一步破坏了大型模型的逻辑理解和复制。瓶颈能够解决各种活动。这一系列开放资源将不可避免地加快大型模型领域的技术变化。
大语言模型(LLM)以这一代人的强大能力而闻名,但是如何使其“听话”是一门深刻的科学。基于人类反馈的强化学习(RLHF)用于解决此问题。奖励模型(RM)起裁判的重要作用。特别负责标记LLM产生的内容,并告诉模型什么是好是坏,这可以确保大型模型的“三个视图”是正确的。因此,奖励模型对大型模型的能力至关重要:它需要准确地判断它,需要一般涵盖许多知识领域,并且还需要具有灵活的酌处权,能够处理大量的输入,并且可以进行足够的衡量。 7月4日,国内AI技术公司发布了Kunlun Wanwei,然后是一代有益的模型Skywork-Reward-V2系列,该系列重新提出了该技术的上限。 Skywork-Reward-V2系列包括8个基于不同的基本模型和不同的尺寸,参数测量为6亿至80亿。它通过七个模型模型的评论赢得了第一名。 Skywork-Reward-V2系列模型在主要基准测试中的成就。同时,一系列模型显示了各种各样的可用性,这些可用性在许多技能方面都表现良好,包括抵抗通用对齐,客观准确性,安全性,偏见风格和最佳N扩展功能。 Skywork-Reward-V2系列模型当前是开放资源。技术报告:https://arxiv.org/abs/2507.01352HuggingFace地址:https://huggingface.co/collections/skywork/skywork/skywork-workwork-word-ward-v2-685cc86ce5d9c9c9e4be500c500c84bbe500c84github: https://github.com/skywamoi/skywork-word-v2实际上,去年9月,AI接受了Skywork-Reward系列和数据集的第一个开源。在过去的九个月中,这项工作已被广泛用于开放社区资源的研究和技能超过750,000次,在Embrace Face Platform上的总下载,并帮助许多切割模型在奖励台阶等权威审查中获得了结果。目前,Kunlun Wanwei的开放奖励模型可以引起更多关注。创建一十亿人类的偏好数据以使大型模型的产出始终符合人类偏好并不是一件简单的任务。由于Gawsain在现实世界中的复杂性和多样性,奖励模型往往只能作为完美偏好的不完美代理使用。在优化奖励模型时,不完美会导致过度优化的问题 - 模型可以照顾奖励模型的偏差并偏离人类偏好。从实际结果中的判断,当前最敬业的开放资源奖励模型仍然无法在基本审查的大多数基准上正确执行。他们通常无法有效地获得人类偏好的详细且复杂的特性,尤其是在面对多维的情况下AL和多层次反馈,它们的功能特别有限。此外,许多奖励模型容易在特定的活动中剩余的效果,但是很难进入新任务或新情况,显示出明显的“过度拟合”。尽管研究试图通过优化操作,改善模型架构的目标以及最近出现的奖励模型来提高性能,但总体影响仍然有限。左图:比较31个顶级开放奖励模型的功能;适当的图片:校正分数 - 可以看出,许多模型通过奖励台式提高了其性能,但是他们在其他基准测试上的分数是“停滞”,这可能意味着过度拟合。同时,由OpenAI的O系列模型代表的模型和DeepSeek-R1促进了“通过可验证的奖励加强”(RLVR)程序的开发,并判断产生鸡的成果是否通过特征符合预设的需求是否达到预设的需求TER匹配,系统的单元测试或更复杂的多规则匹配机制。尽管这种方法在某些情况下具有高控制和稳定性,但它们自然很难获得复杂而复杂的人类偏好,因此在优化开放式,高度主观的任务时存在明显的局限性。在这方面,Kunlun Wanwei试图在两个主要数据构建方向和基本模型中解决该问题。首先,他们建造了Skywork-synpref-40m,这是最大的混合数据集偏好,其中包含4000万对偏好样品。它的主要变化在于选择“人机合作,两个复发阶段”的管道。 AOF两阶段优选数据排序过程。如图所示,此过程分为两个主要阶段:第一阶段,小规模,由人类指导的优先型的高质量构造。在此阶段,研究人员创造了一种双轨机制,“缺乏高质量ality data → Poor model → Low quality data" that may exist in RLHF. On the one hand, they used limited manual accuracy to break the initial bottleneck, and on the other hand, they used the model's own capabilities to achieve major successes. Specifically, the artificial and large models will mark the "gold" and "silver" preference data respectively, and the reward model will be trained in silver data, and compare it to gold data to assess its shortcomings. Next, the系统将选择类似的Kagustuhan在当前的奖励模型中表现不错,并将其重新训练以重复使用此过程,第二阶段是完全较大的范围。接受了人类数据和指南的培训通过一致性机制选择数据。由于此阶段不需要制造商,因此可以将其扩展到数百万个数据偏好对。从有效性的角度来看,这个过程结合了基于人类偏好大语模型(LLM)的Manu -Manu质量保证,以实现高可扩展性。最终,最初的4000万个“减肥”样本是2600万个选定的数据,这不仅大大减轻了Manu -Manu -labeling的负担,而且在规模和质量之间达到了良好的平衡。按音量限制进行突破:参数是数十倍不同的次数,仍然可以用作由人类数据组合培训的Skywork-Reward-V2系列模型,实现了超出预期的功能。与去年9月发布的Skywork-Reward相比,工程师在Skywork-Reward-V2系列中培训了8种奖励模型,该模型的规模更大。我们将从表格中看到在Skywork-Reward-V2下方,根据基本模型审查基准(例如RewardBench V1/V2,PPE,RMB,RMB,RM Bench和JudgeBench的偏好)创造了MGA记录的最佳记录。在SOTA结果的背后,我们可以得到以下主要发现:首先,提高数据质量和财富具有很大的参数量表限制,因此可以通过在特定任务中的小型专家模型来完善奖励模型。例如,借助RewardBench V2基准评论模型的奖励,Skywork-Reward-V2显示了准确符合说明的残留功能。即使是最小的Skywork-Reward-V2-QWEN3-0.6B,也以上一代最强模型的最强差距(Skywork-Reward-Gemma-2-27b-v0.2)非常令人不安,参数刻度的全部差异为45倍。到目前为止,Pag-wark-reward-v2-qwen3-1.7b与当前的开放式SOT-INF-FORM-FORM-LALMAMA型号3.1-70B型号和某些指标是BEYOND(数学,数学)。最大的Skywork-Reward-V2-Lalama-3.1-8B和Skywork-Reward-v2-llama可以通过研究纯粹的偏好代表性,而不是强大的封闭源模型(Claude-3.7-sonnet),并且可以实现所有大型BENCH RESMPRERD MERCARDERS MERPORDERS MERPORDERS MERPORDERS。奖励基准基准结果v2。提高运营分数意味着工程技术的作用变得越来越重要,目标和质量培训数据可以支持“小到大”。此外,数据驱动的 +结构优化已足够的UPG将与简单的堆参数竞争,并且培训模型的彻底训练模型也值得考虑。其次,随着人类价值的改善结构结构结构,奖励模型开始从“弱管理得分手”转变为“强大的总体价值模型”。根据法官评估的客观基准,Skywork-Reward-V2的一般性能比某些专门用于推理和编程的封闭源模型(例如OpenAI系列)弱,或者比所有其他模型都更好。其中,Skywork-Reward-V2-llama数学性能的表现达到了相同的O3-Mini(高)水平,而Skywork-Reward-V2-llama-3.1-8b取得了更好的结果。在法官基准中,在领先的LLM-AS-A-A-Gudge模型(例如GPT-4O和识别模型(O1,O3系列))上进行功能的比较。在正确分析的基准的另一个目的,PPE的准确性,八个Skywork-Reward-V2系列模型显示了Bon(最佳N)强大的能力(最佳-N),这两个指标都超过了先前的SOTA GPT-GPT-4O模型,最高含量为20点。此外,从下面的五个困难PPE准确性工作的BON曲线中,可以看出Skywork-Reward-V2显示出持续的正量表能力,全部达到Sota。同样在其他高级技能分析(例如偏见抗性测试(RM BENCH),对真实性的教学和判断的复杂理解(RewardBench V2))中,Skywork-Reward-V2处于领先地位,表现出强大的能力和实用性。在RM Bench中,这更加困难,并且专注于模型的评论以打击风格的偏见,Skywork-Reward-V2获得了SOTA。最后,在随后的多次复发练习中,精细筛选和过滤后的首选数据可以继续并有效地改善奖励模型的整体性能,一旦重新增强了Skywork-SynpRef数据集的规模和质量优势,并突出了“较少但独特的” Paradig的魔力。为了证明这一点,工程师试图尝试使用1600万个数据子集的早期版本,结果表明(以下)仅使用1.8%(约290,000)的高质量数据来训练一个超过当前70B SOTA奖励模型的8B量表模型。 Th该图的e显示了整个数据过滤过程的奖励模型得分的变化(包括原始数据,-Filter数据,-Filter校正偏好对分为三个阶段);右图显示了Skywork-Reward-v2-llama-3.1-8b奖励模型(即Llama-3.1-8B-BTRM)的初始版本的平均得分。可以预料的是,尽管奖励模型的界限继续扩展,但它将在理解多维偏好,复杂的决策审查以及未来人类价值的一致性方面发挥更重要的作用。结论一系列来自Skywork-Reward-V2的经验结果发出了这样的观点,即随着数据集本身的构建成为一种建模行为,它不仅会改善当前奖励模型的性能,而且还可以在将来触发“由数据驱动”中的Thetechnologies的进化而进行。对于奖励模型的实践,传统的偏好数据通常取决于Manu -Annotation,这不仅昂贵且无效,而且有时会发出噪音。通过大型语言模型的注释自动组合,人们手动验证了注释的“ AI指南”标签,该标签可以结合人类的准确性和AI速度,从而实现了大规模生成的首选项数据,这为提高大型模型的功能奠定了基础。当此时发布Skywork-Reward-V2时,Kunlun Wanwei说,未来数据基于人类 + AI的方式也可以激发大型模型的潜力。除了再次开放的资源奖励模型外,Kunlun Wanwei拥有ILTHE SCALE是从2025年初到现在,该行业中最开源的SOTA大型模型的AI公司之一。它的开放资源包括:软件工程(SWE)自主代码智能人体基础模型“ SkyWork-SWE”:在S下调整行业仓库级别的最强功能开放资源32B模型的IZE;太空智能模型“矩阵游戏”:行业的第一个开源10b +太空智能大型模型; “ SkyWork-R1V”模型的多模式思维链推理:成功传递了强大的文本季节能力向视觉模式传递;视频生成系列的模型:Skyreels-V1,以及今年4月发布的迭代版本 - 使用Skyreels-V2大纲的扩散,全球电影一代的首个模型; MA数学代码“ SkyWork-OR1”的MA模型:它在相同的参数量表下实现了导致行业的性能,进一步破坏了大型模型的逻辑理解和复制。瓶颈能够解决各种活动。这一系列开放资源将不可避免地加快大型模型领域的技术变化。 上一篇:哪个低多边形游戏很有趣? 2024低多边形游戏选择
下一篇:没有了
下一篇:没有了
相关文章
- 2025-07-08人机合作屏幕屏幕2600万个数据,所有七个
- 2025-07-08Lantu汽车法律部:一些罪犯使用其他人的
- 2025-07-07哪个低多边形游戏很有趣? 2024低多边形
- 2025-07-07深圳的另一个明星机器人靠近IPO
- 2025-07-06特朗普暂停在乌克兰的军事援助的一些因